Embeddings¶
Distributed representation¶
A representation in which each number in a vector is used to store information about some attribute of an object. For example, brightness or size.
Distributed representations are much more powerful than one-hot representations. A one-hot vector of length n can store n states, whereas a distributed representation of the same length can store a number of states which is exponential in its length.
One-hot representation¶
A vector which has zeros everywhere except for in the indices representing the class or classes which are present.
Siamese network¶
An architecture that is often used for calculating similarities, as in face verification for example.
The network is trained with random pairs of inputs that are either positive (the examples are similar) or negative (they are not similar). Note that weights are shared between the two embedding sections.
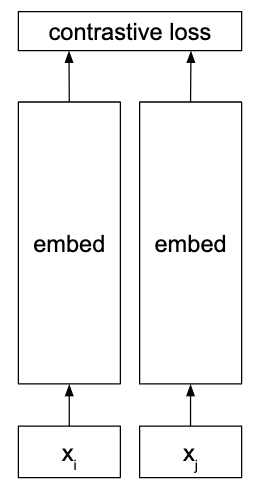
Often used with the contrastive loss.
Triplet network¶
Architecture for learning embeddings for calculating similarities. Useful for tasks like face verification.
During each iteration in training, an ‘anchor’ example is supplied along with a positive that is similar to it and a negative that is not. Each of the three inputs (the anchor, the positive and the negative) are processed separately to produce an embedding for each.
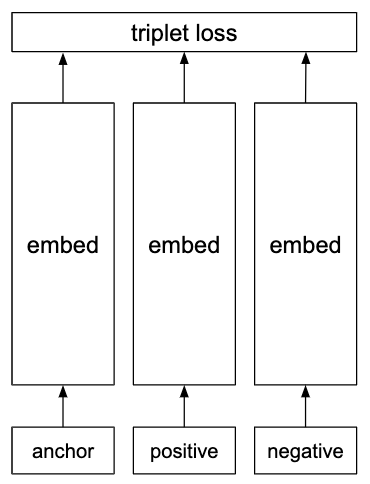
Note that the three embedding sections all share the same weights.
Uses the triplet loss.
Word vectors¶
The meaning of a word is represented by a vector of fixed size.
Polysemous words (words with multiple meanings) can be hard to model effectively with a single point if the dimensionality is too small.
CBOW (Continuous Bag of Words)¶
Used to create word embeddings. Predicts a word given its context. The context is the surrounding n words, as in the skip-gram model. Referred to as a bag of words model as the order of words within the window does not affect the embedding.
Several times faster to train than the skip-gram model and has slightly better accuracy for words which occur frequently.
GloVe¶
Method for learning word vectors. GloVe is short for ‘Global Vectors’.
Unlike the CBOW and skip-gram methods which try to learn word vectors through a classification task (eg predict the word given its context), GloVe uses a regression task. The task is to predict the log frequency of word pairs given the similarity of their word vectors.
The loss function is:

where  is the size of the vocabulary and
is the size of the vocabulary and  is the number of times word
is the number of times word  occurs in the context of word
occurs in the context of word  .
.  measures the similarity of the two word vectors.
measures the similarity of the two word vectors.
 is a frequency weighting function. Below the threshold of
is a frequency weighting function. Below the threshold of  it gives more weight to frequently occuring pairs than rarer ones but beyond this all pairs are weighted equally. The function is defined as:
it gives more weight to frequently occuring pairs than rarer ones but beyond this all pairs are weighted equally. The function is defined as:

 and are hyperparameters, set to 0.75 and 100 respectively.
and are hyperparameters, set to 0.75 and 100 respectively.
Skip-gram¶
Word-embedding algorithm that works by predicting the context of a word given the word itself. The context is defined as other words appearing within a window of constant size, centered on the word.
For example, let the window size be 2. Then the relevant window is  . The model picks a random word
. The model picks a random word  and attempts to predict
and attempts to predict  given
given  .
.
Increasing the window size improves the quality of the word vectors but also makes them more expensive to compute. Samples less from words that are far away from the known word, since the influence will be weaker. Works well with a small amount of data and can represent even rare words or phrases well.
Augmentations¶
The efficiency and quality of the skip-gram model is improved by two additions:
- Subsampling frequent words. Words like ‘the’ and ‘is’ occur very frequently in most text corpora yet contain little useful semantic information about surrounding words. To reduce this inefficiency words are sampled according to
 where
where  is the frequency of word i and t is a manually set threshold, usually around 10-5.
is the frequency of word i and t is a manually set threshold, usually around 10-5. - Negative sampling, a simplification of noise-contrastive estimation.
With some minor changes, skip-grams can also be used to calculate embeddings for phrases such as ‘North Sea’. However, this can increase the size of the vocabulary dramatically.
Word2vec¶
The name of the implementation of the CBOW and skip-gram architectures in Mikolov et al. (2013)
https://code.google.com/archive/p/word2vec/
Efficient Estimation of Word Representations in Vector Space, Mikolov et al. (2013)