Layers¶
Affine layer¶
Synomym for fully-connected layer.
Attention¶
An attention layer takes a query vector and uses it, combined with key vectors, to compute a weighted sum of value vectors. If a key is determined to be highly compatible with the query the weight for the associated value will be high.
Attention has been used to improve image classification, image captioning, speech recognition, generative models and learning algorithmic tasks, but has probably had the largest impact on neural machine translation.
Computational complexity¶
Let  be the length of a sequence and
be the length of a sequence and  be the embedding size.
be the embedding size.
A recurrent network’s complexity will be  .
.
A soft attention mechanism must look over every item in the input sequence for every item in the output sequence, resulting in complexity that is quadratic in the sequence length:  .
.
Additive attention¶
Let  be the input sequence and
be the input sequence and  be the output sequence.
be the output sequence.
There is an encoder RNN whose hidden state at index  we refer to as
we refer to as  . The decoder RNN’s state at time is
. The decoder RNN’s state at time is  .
.
Attention is calculated over all the words in the sequence form a weighted sum, known as the context vector. This is defined as:

where  is the jth element of the softmax of
is the jth element of the softmax of  .
.
The attention given to a particular input word depends on the hidden states of the encoder and decoder RNNs.

The decoder’s hidden state is computed according to the following expression, where  represents the decoder.
represents the decoder.

To predict the output sequence we take the decoder hidden state and the context vector and feed them into a fully connected softmax layer  which gives a distribution over the output vocabulary.
which gives a distribution over the output vocabulary.

Dot-product attention¶
Returns a weighted average over the values,  .
.

Where  is the query matrix,
is the query matrix,  is the matrix of keys and is the matrix of values.
is the matrix of keys and is the matrix of values.  determines the weight of each value in the result, based on the similarity between the query and the value’s corresponding key.
determines the weight of each value in the result, based on the similarity between the query and the value’s corresponding key.
The queries and keys have the same dimension.
The query might be the hidden state of the decoder, the key the hidden state of the encoder and the value the word vector at the corresponding position.
Scaled dot-product attention¶
Adds a scaling factor  , equal to the dimension of :
, equal to the dimension of :

This addition to the formula is intended to ensure the gradients do not become small when  grows large.
grows large.
Hard attention¶
Form of attention that attends only to one input, unlike soft attention. Trained using the REINFORCE algorithm since, unlike other forms of attention, it is not differentiable.
Self-attention¶
TODO
Soft attention¶
Forms of attention that attend to every input to some extent, meaning they can be trained through backpropagation. Contrast with hard attention, which attends exclusively to one input.
Convolutional layer¶
Transforms an image according to the convolution operation shown below, where the image on the left is the input and the image being created on the right is the output:
TODO
Let  be a matrix representing the image and
be a matrix representing the image and  be another representing the kernel, which is of size NxN.
be another representing the kernel, which is of size NxN.  is the matrix that results from convolving them together. Then, formally, convolution applies the following formula:
is the matrix that results from convolving them together. Then, formally, convolution applies the following formula:

Where  .
.
Padding¶
Applying the kernel to pixels near or at the edges of the image will result in needing pixel values that do not exist. There are two ways of resolving this:
- Only apply the kernel to pixels where the operation is valid. For a kernel of size k this will reduce the image by
 pixels on each side.
pixels on each side. - Pad the image with zeros to allow the operation to be defined.
Efficiency¶
The same convolution operation is applied to every pixel in the image, resulting in a considerable amount of weight sharing. This means convolutional layers are quite efficient in terms of parameters. Additionally, if a fully connected layer was used to represent the functionality of a convolutional layer most of its parameters would be zero since the convolution is a local operation. This further increases efficiency.
The number of parameters can be further reduced by setting a stride so the convolution operation is only applied every m pixels.
1x1 convolution¶
These are actually matrix multiplications, not convolutions. They are a useful way of increasing the depth of the neural network since they are equivalent to  , where is the activation function.
, where is the activation function.
If the number of channels decreases from one layer to the next they can be also be used for dimensionality reduction.
Dilated convolution¶
Increases the size of the receptive field of the convolution layer.
Used in WaveNet: A Generative Model for Raw Audio, van den Oord et al. (2016).
Separable convolution/filter¶
A filter or kernel is separable if it (a matrix) can be expressed as the product of a row vector and a column vector. This decomposition can reduce the computational cost of the convolution. Examples include the Sobel edge detection and Gaussian blur filters.

Transposed convolutional layer¶
Sometimes referred to as a deconvolutional layer. Can be used for upsampling.
Pads the input with zeros and then applies a convolution. Has parameters which must be learned, unlike the upsampling layer.
Dense layer¶
Synomym for fully-connected layer.
Fully-connected layer¶
Applies the following function:

is the activation function.  is the output of the previous hidden layer.
is the output of the previous hidden layer.  is the weight matrix and
is the weight matrix and  is known as the bias vector.
is known as the bias vector.
Hierarchical softmax¶
A layer designed to improve efficiency when the number of output classes is large. Its complexity is logarithmic in the number of classes rather than linear, as for a standard softmax layer.
A tree is constructed where the leaves are the output classes.
Alternative methods include Noise Contrastive Estimation and Negative Sampling.
Inception layer¶
Using convolutional layers means it is necessary to choose the kernel size (1x1, 3x3, 5x5 etc.). Inception layers negate this choice by using multiple convolutional layers with different kernel sizes and concatenating the results.
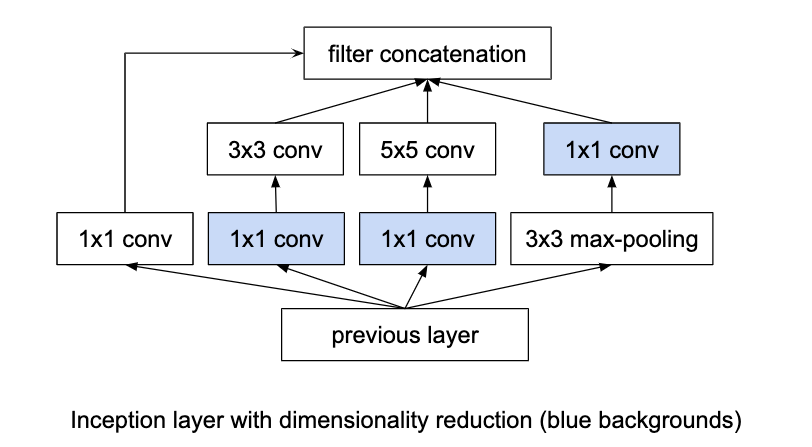
Padding can ensure the different convolution sizes still have the same size of output. The pooling component can be concatenated by using a stride of length 1 for the pooling.
5x5 convolutions are expensive so the 1x1 convolutions make the architecture computationally viable. The 1x1 convolutions perform dimensionality reduction by reducing the number of filters. This is not a characteristic necessarily found in all 1x1 convolutions. Rather, the authors have specified to have the number of output filters less than the number of input filters.
9 inception layers are used in GoogLeNet, a 22-layer deep network and state of the art solution for the ILSVRC in 2014.
Pooling layer¶
Max pooling¶
Transforms the input by taking the max along a particular dimension. In sequence processing this is usually the length of the sequence.
Mean pooling¶
Also known as average pooling. Identical to max-pooling except the mean is used instead of the max.
RoI pooling¶
Used to solve the problem that the regions of interest (RoI) identified by the bounding boxes can be different shapes in object recognition. The CNN requires all inputs to have the same dimensions.
The RoI is divided into a number of rectangles of fixed size (except at the edges). If doing 3x3 RoI pooling there will be 9 rectangles in each RoI. We do max-pooling over each RoI to get 3x3 numbers.
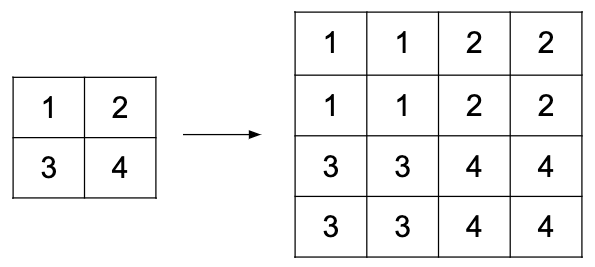
Upsampling layer¶
Simple layer used to increase the size of its input by repeating its entries. Does not have any parameters.
Example of a 2D upsampling layer: